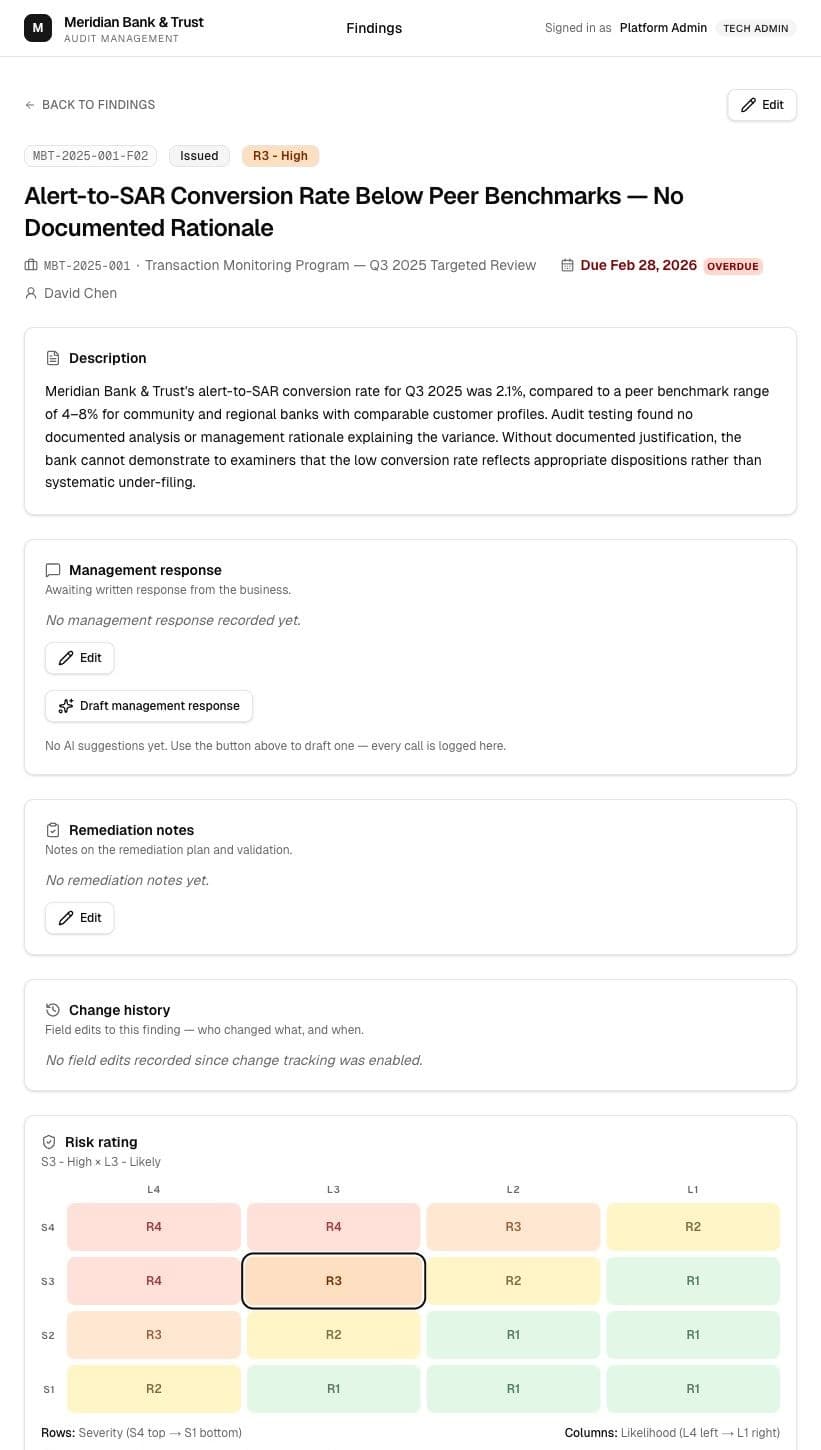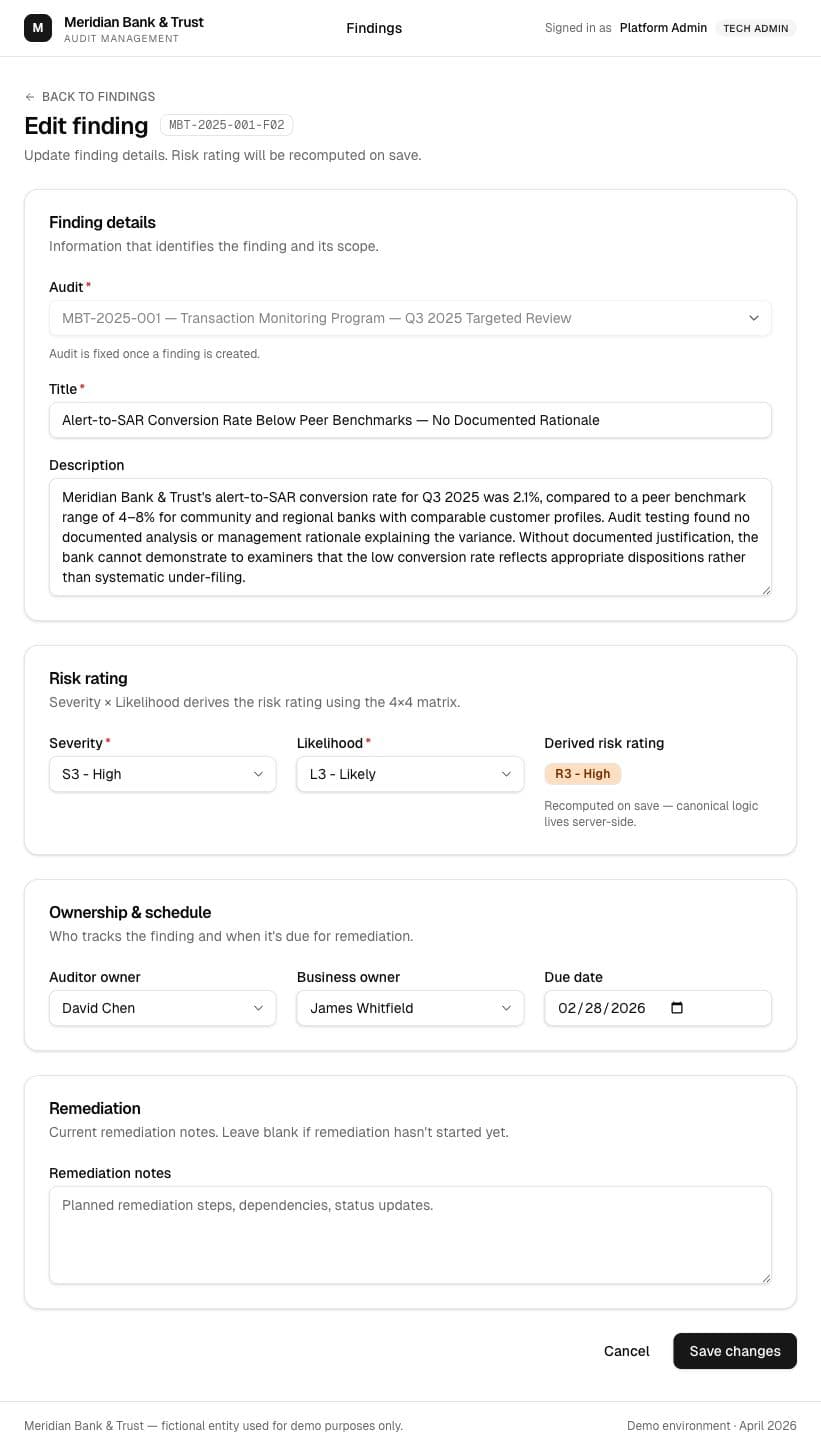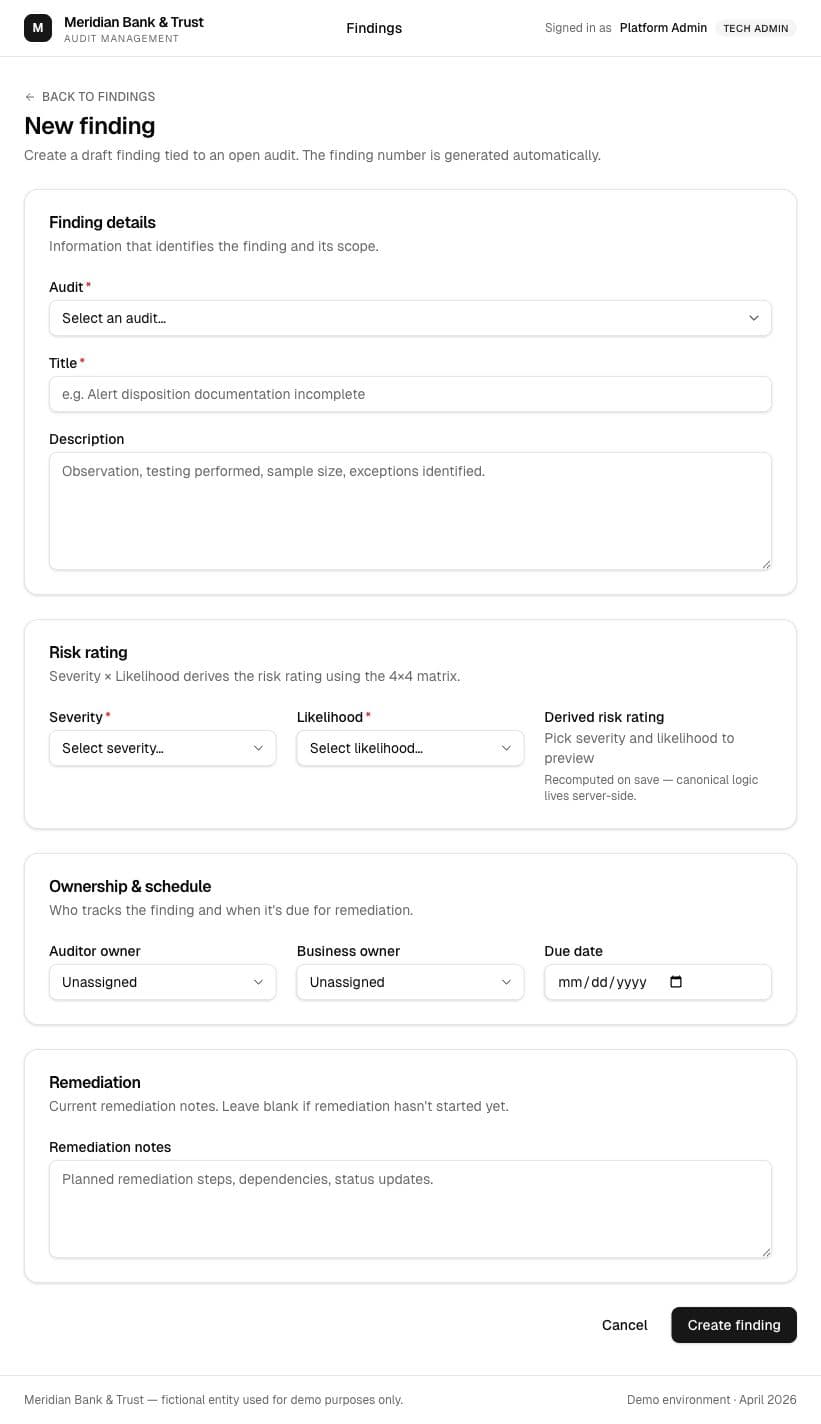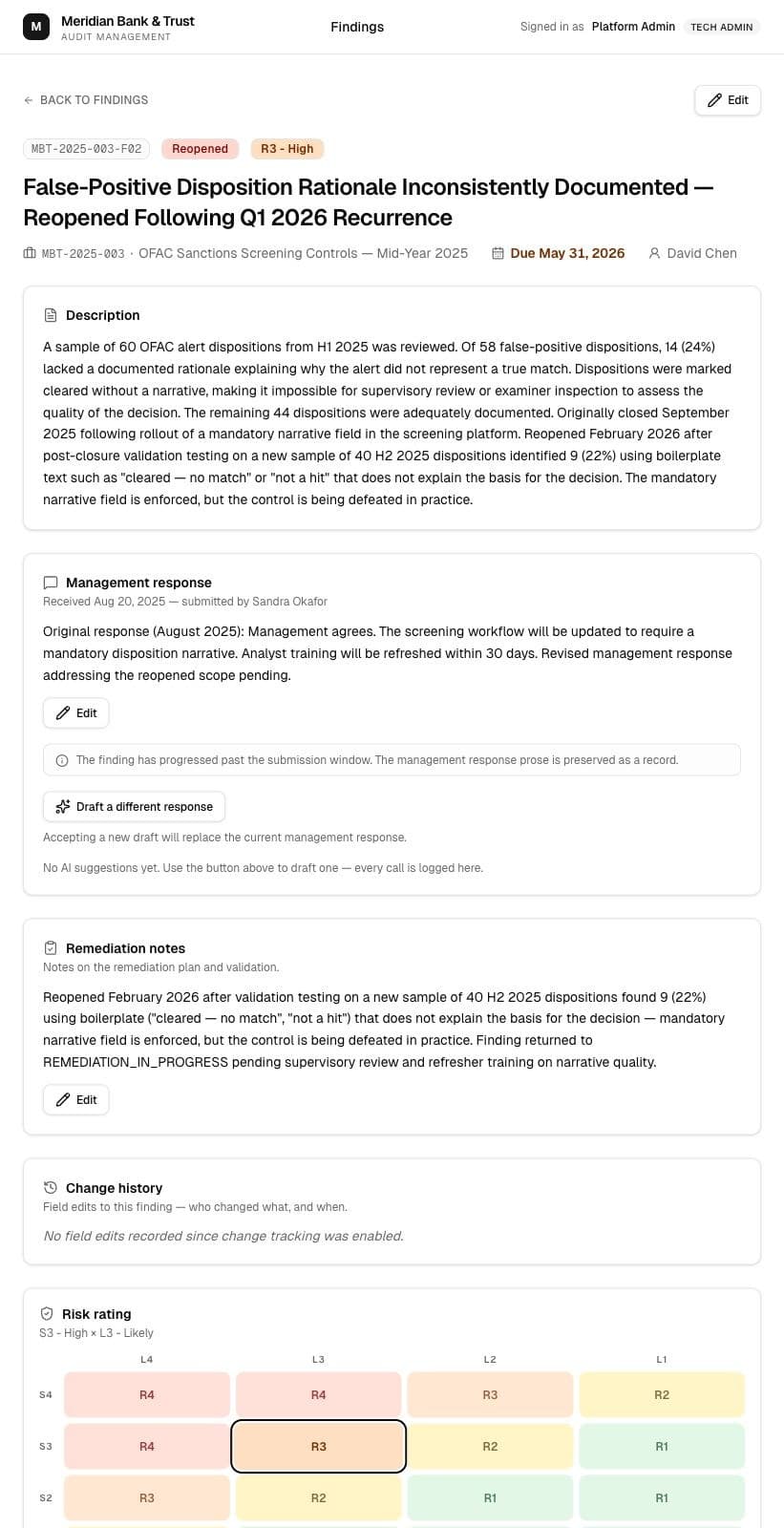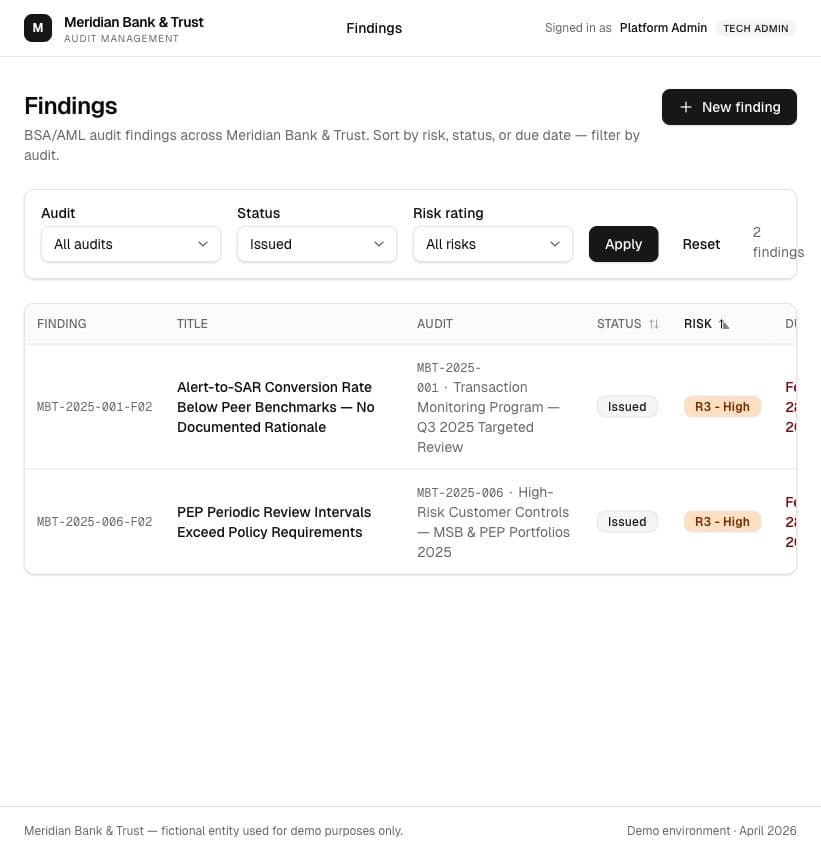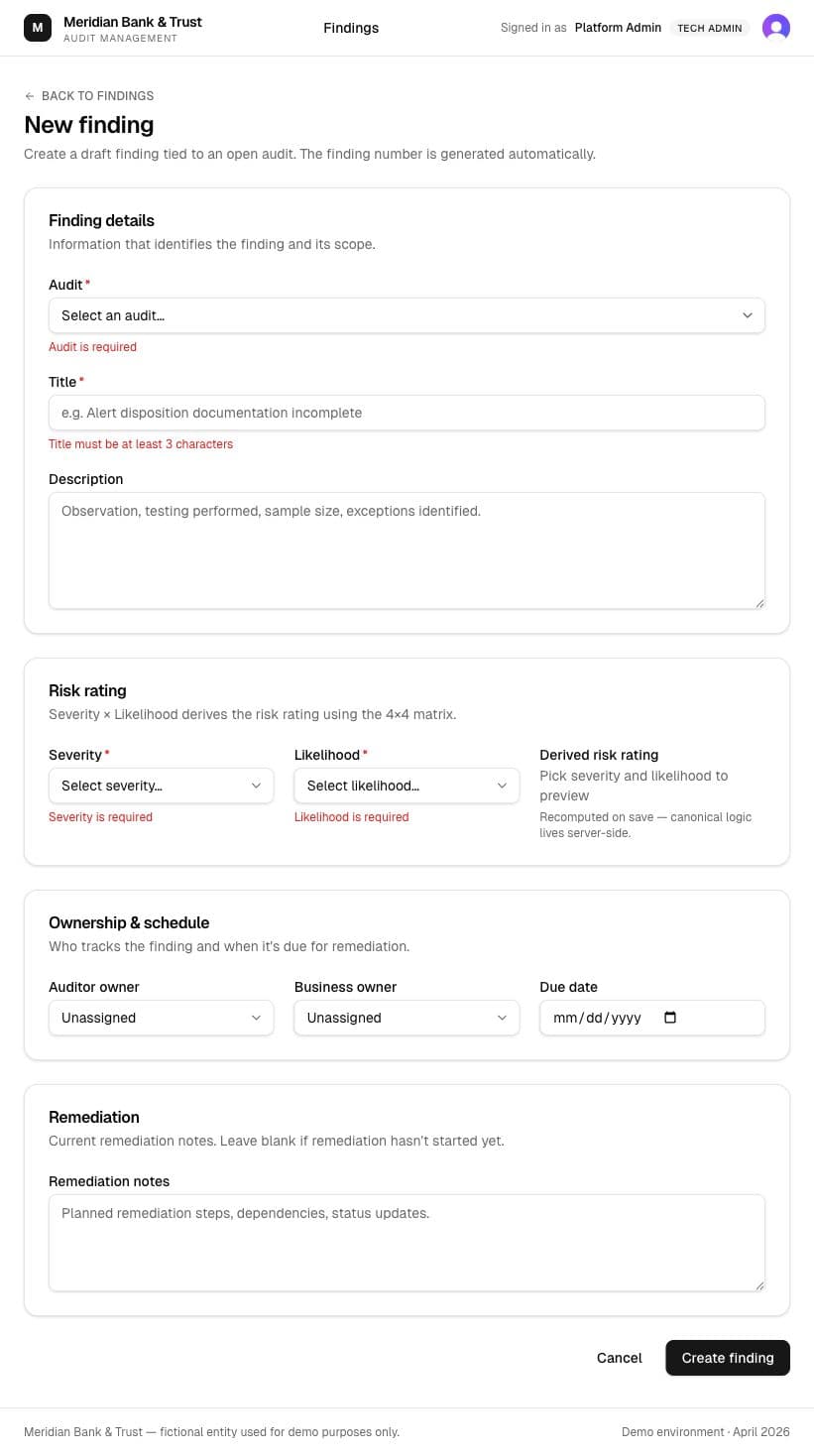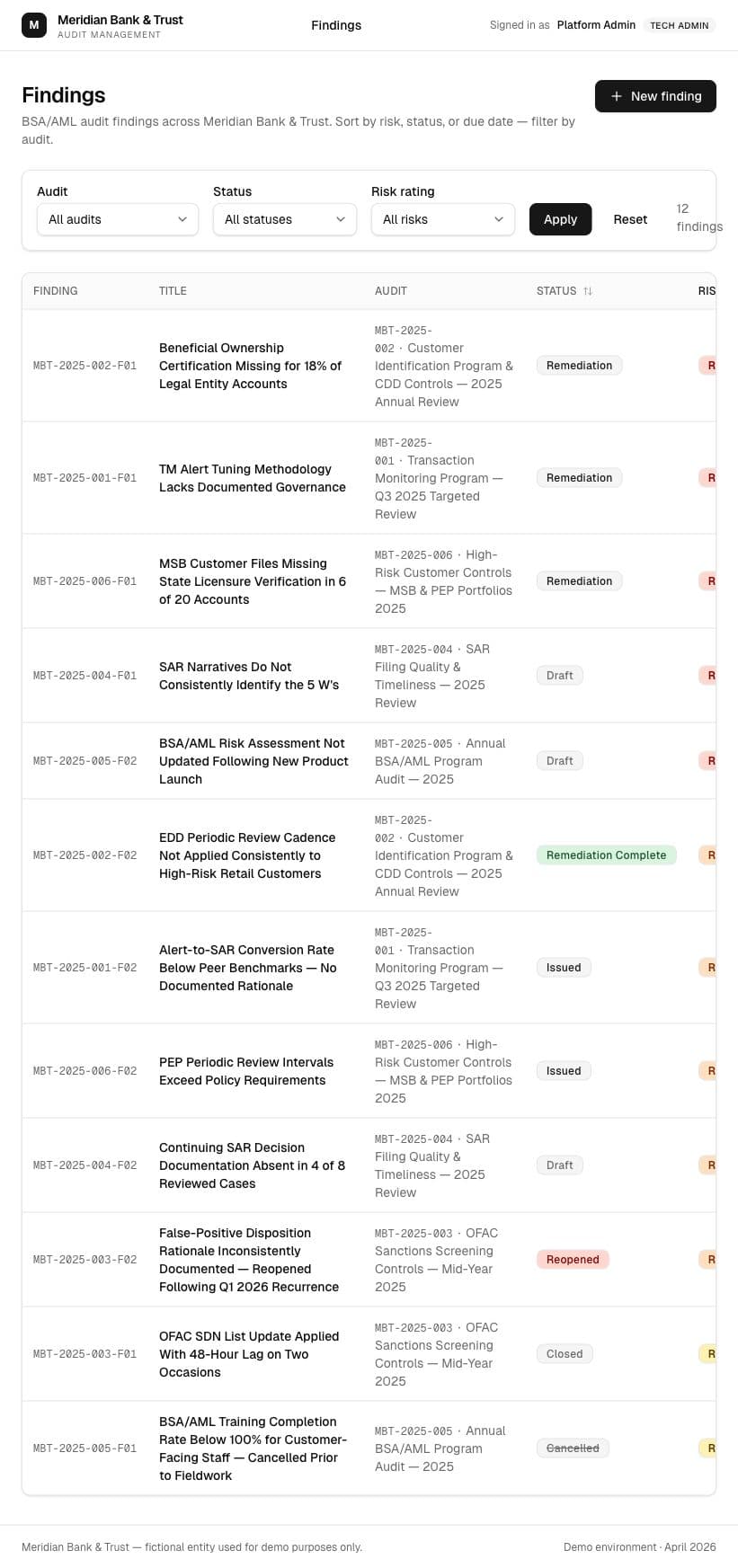
The better idea came from testing the first one
I started with a citation helper because it looked like an obvious AI feature. Testing it made the better answer clear: experienced auditors do not need much help picking an FFIEC section. The higher-friction work was drafting formal management responses, so I changed direction.